The problem with a file level backup is that when you have many files (as opposed to a few large files) the backup will take much much longer. Backups need to be able to detect diffs and only backup what is needed to be efficient. Avoiding RSYNC like applications for backup whenever you can is ideal.
Block level and filesystem level backups are always faster. I understand this may not be suitable for everyone but I always expect whichever backup applications I choose to create a file in my backup destination that is an archive filled with immutable snapshots of the filesystem I am backing up. I almost always now choose my filesystem based on my backup strategy . Here are some examples of filesystems and the best ways to back them up.
NTFS (windows): Your backups should be done via volume shadow copy provider. Almost all mainstream backup software use this method for backups (Acronis, Veeam, built in windows Etc).
Ext4/XFS: there are a few different ways to peel this banana. You can use LVM to help you create your snapshots. Some backup applications will install a block filesystem backup driver to perform your backups. On Linux based NAS like QNAP, often they will have a backup application built in that will let you ship snapshots to another data location. This is ideal as then you don’t need a third party application to perform your backups and your backups will be short and frequent.
ZFS: I love ZFS (I am biased).The key is to do this with snapshots as well. Have another ZFS server somewhere and ship your snapshots to it with Zsnapsend or SANOID (a Zsnapsend policy based backup). Backing up ZFS to cloud providers is less than ideal and usually serves better as a backups destination. Backing up data inside of ZFS datasets ends up being an RSYNC like process if you can’t touch the snapshots with your backup software. At that point I would suggest using something that has a backup driver inside of it. I’ve in the past run a LXC container on the host and installed the Acronis agent with its block driver in the container and mounted by datasets as locations inside the container to get around this.
Virtualization: always grab the backup from the Host system. A lot of times this means you can lift and shift multiple VMs at greater speed this way. The filesystem won’t matter at this point (unless you’re using VM ware tools to perform a VSS snapshot before each backup in your VM before each snapshot).
Use Changed Block Tracking whenever you can.
I hope this helps you or someone else reading this. Thanks.
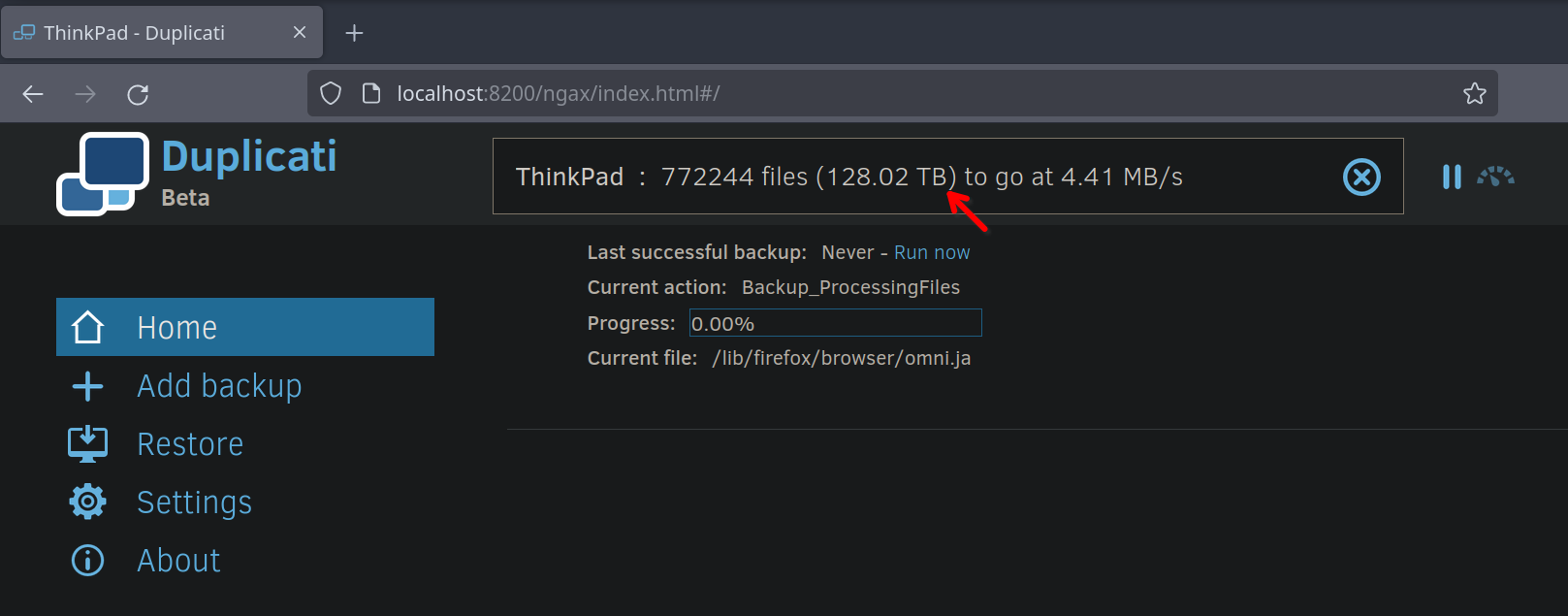
Edit: Just realized it says 128TB in the picture and not GB. You’re gonna need the Lord’s help. That or a 10Gb link to another seriously fast NAS on your network that will let you sustain writes above 1GBs. That would only take about a day.
{kind=link}
I tried this exact application and I feel like I learned a lot about backups in the process. I like to think about it like this: (info dump)
There are basically these three backups:
block level, filesystem level, file level backups.
The problem with a file level backup is that when you have many files (as opposed to a few large files) the backup will take much much longer. Backups need to be able to detect diffs and only backup what is needed to be efficient. Avoiding RSYNC like applications for backup whenever you can is ideal.
Block level and filesystem level backups are always faster. I understand this may not be suitable for everyone but I always expect whichever backup applications I choose to create a file in my backup destination that is an archive filled with immutable snapshots of the filesystem I am backing up. I almost always now choose my filesystem based on my backup strategy . Here are some examples of filesystems and the best ways to back them up.
NTFS (windows): Your backups should be done via volume shadow copy provider. Almost all mainstream backup software use this method for backups (Acronis, Veeam, built in windows Etc).
Ext4/XFS: there are a few different ways to peel this banana. You can use LVM to help you create your snapshots. Some backup applications will install a block filesystem backup driver to perform your backups. On Linux based NAS like QNAP, often they will have a backup application built in that will let you ship snapshots to another data location. This is ideal as then you don’t need a third party application to perform your backups and your backups will be short and frequent.
ZFS: I love ZFS (I am biased).The key is to do this with snapshots as well. Have another ZFS server somewhere and ship your snapshots to it with Zsnapsend or SANOID (a Zsnapsend policy based backup). Backing up ZFS to cloud providers is less than ideal and usually serves better as a backups destination. Backing up data inside of ZFS datasets ends up being an RSYNC like process if you can’t touch the snapshots with your backup software. At that point I would suggest using something that has a backup driver inside of it. I’ve in the past run a LXC container on the host and installed the Acronis agent with its block driver in the container and mounted by datasets as locations inside the container to get around this.
Virtualization: always grab the backup from the Host system. A lot of times this means you can lift and shift multiple VMs at greater speed this way. The filesystem won’t matter at this point (unless you’re using VM ware tools to perform a VSS snapshot before each backup in your VM before each snapshot).
Use Changed Block Tracking whenever you can.
I hope this helps you or someone else reading this. Thanks.
Edit: Just realized it says 128TB in the picture and not GB. You’re gonna need the Lord’s help. That or a 10Gb link to another seriously fast NAS on your network that will let you sustain writes above 1GBs. That would only take about a day.