
2·
6 days agoI see, I forgot about tampermonkey. At that point I can also just paste a bookmarklet into the script space itself and enable when needed.
Firefox-based mobile browsers unload pages for me when I tab away (maybe it’s a Samsung killer thing? all outside of the scope of this question tho), which could be an issue, but if I’m careful then this method should do it. Thanks!









{kind=link}
{kind=link}
{kind=link}
{kind=link}
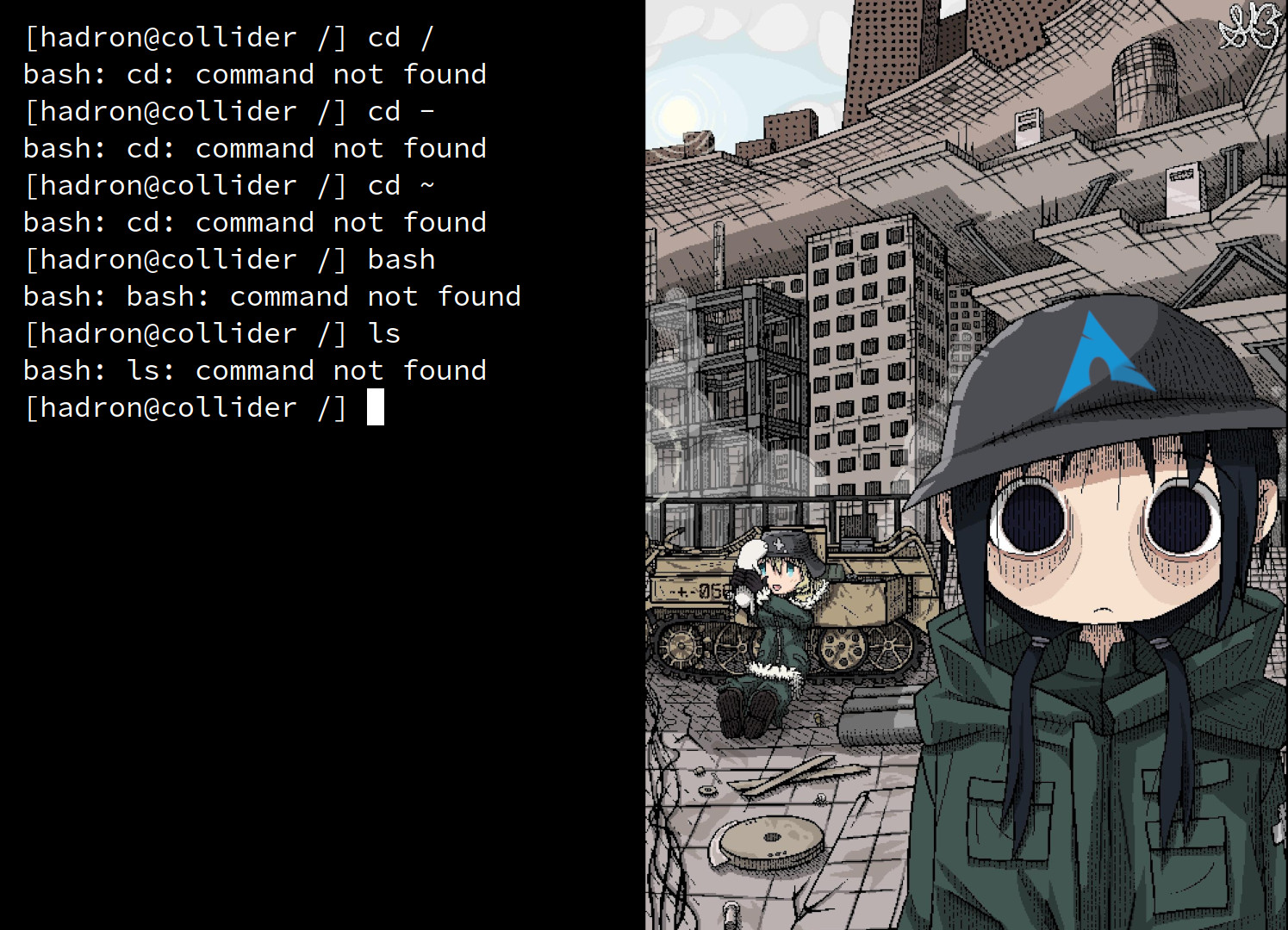
I tried a bunch of boot-from-USB tests and it fixed itself. Woot